In today's technical landscape, systems are often scaled by adding more compute and storage resources to handle growing workloads. This usually means adding more commodity hardware across distributed environments.
But as systems scale out, complexity increases. That is where the CAP theorem becomes important.
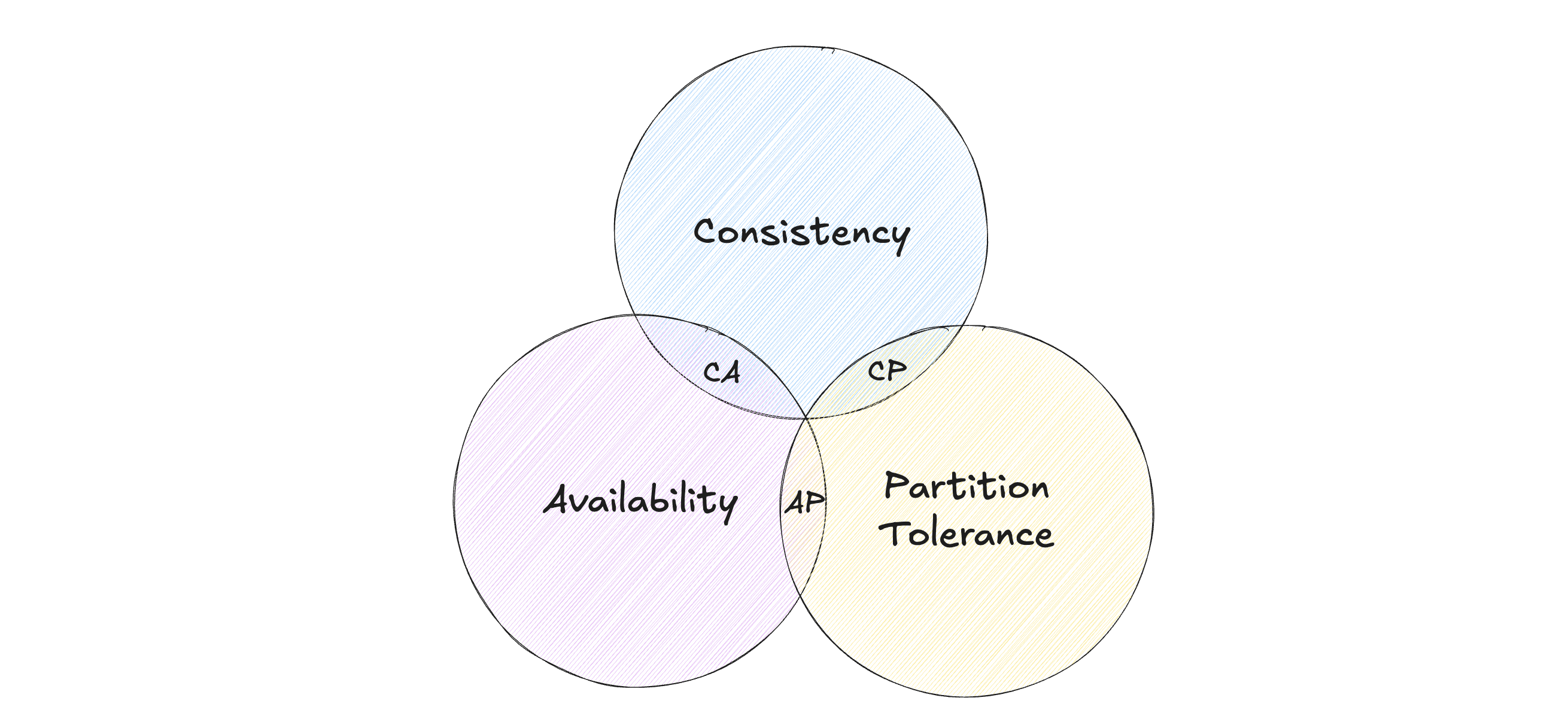
What Is CAP Theorem?
CAP theorem states that a distributed system cannot simultaneously guarantee all three of:
- Consistency
- Availability
- Partition Tolerance
In the presence of a network partition, a system must choose between consistency and availability.
C - Consistency
Consistency means all nodes see the same data at the same time. A client should either get the latest write or an error.
Example of an inconsistent system:
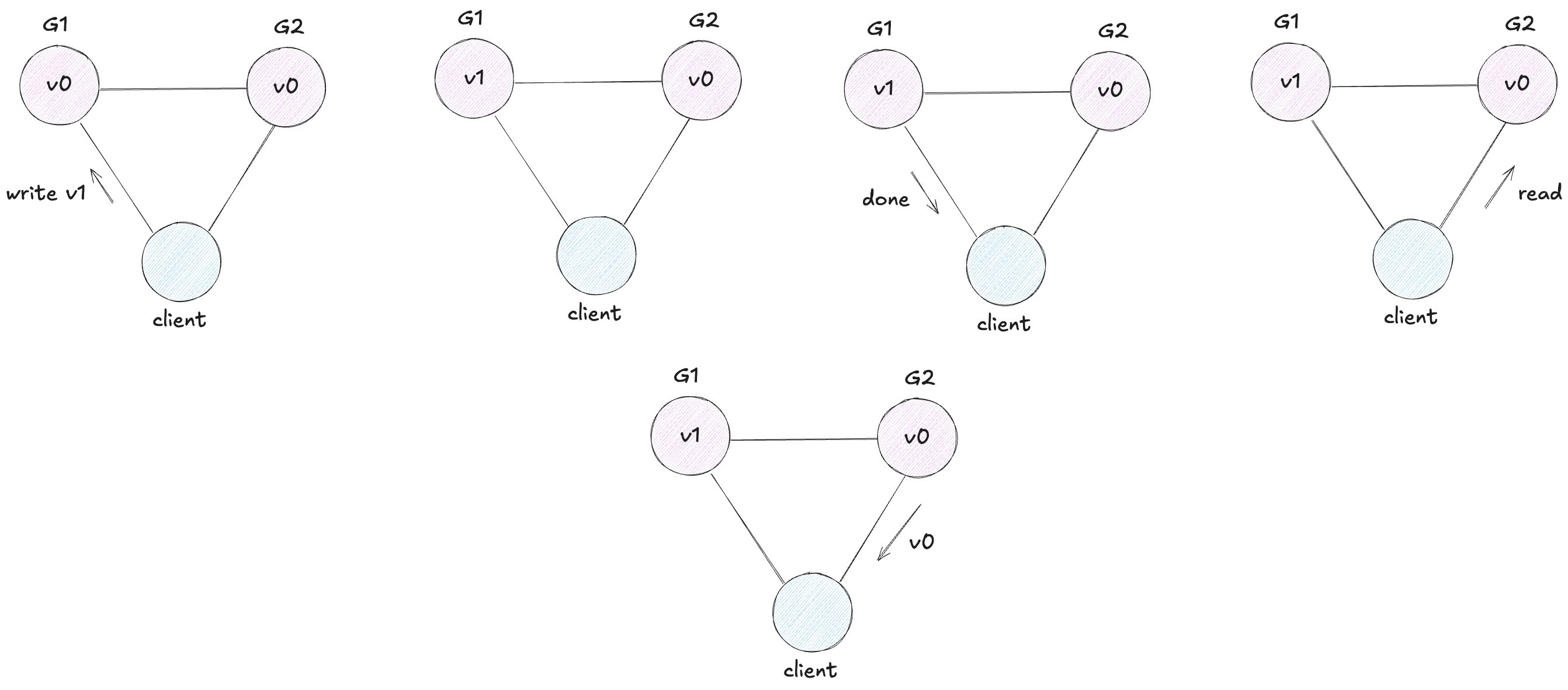
Client writes v1 to G1, gets acknowledgment, then reads from G2 and gets stale value v0.
Example of a consistent system:
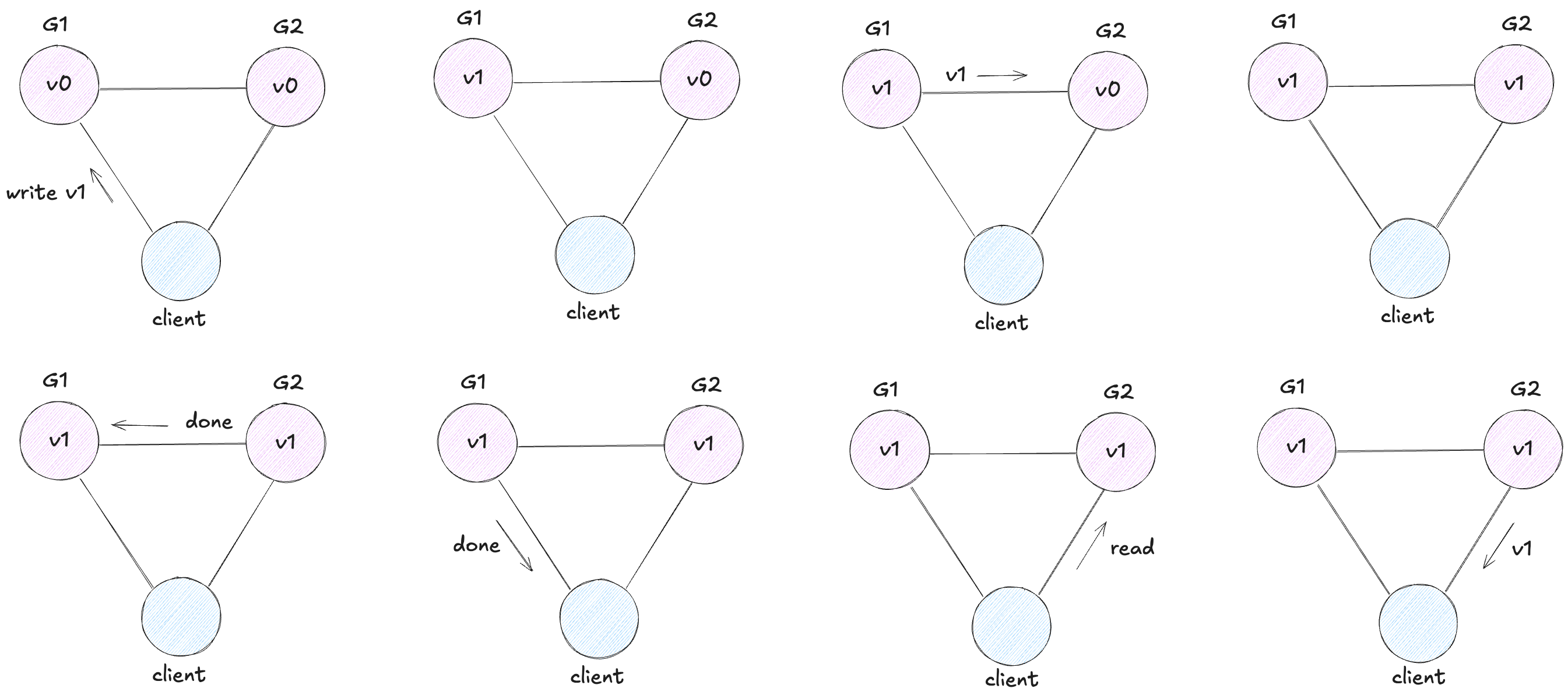
Here, G1 replicates to G2 before acknowledging the write. So reading from G2 returns the latest value v1.
A - Availability
Availability means every request receives a response, even if some nodes fail or network partitions happen. The response may not always contain the latest data, but the system remains reachable.
P - Partition Tolerance
Partition tolerance means the system keeps operating even when nodes cannot communicate due to network issues.
For example, if all messages between G1 and G2 are dropped, the system looks like:
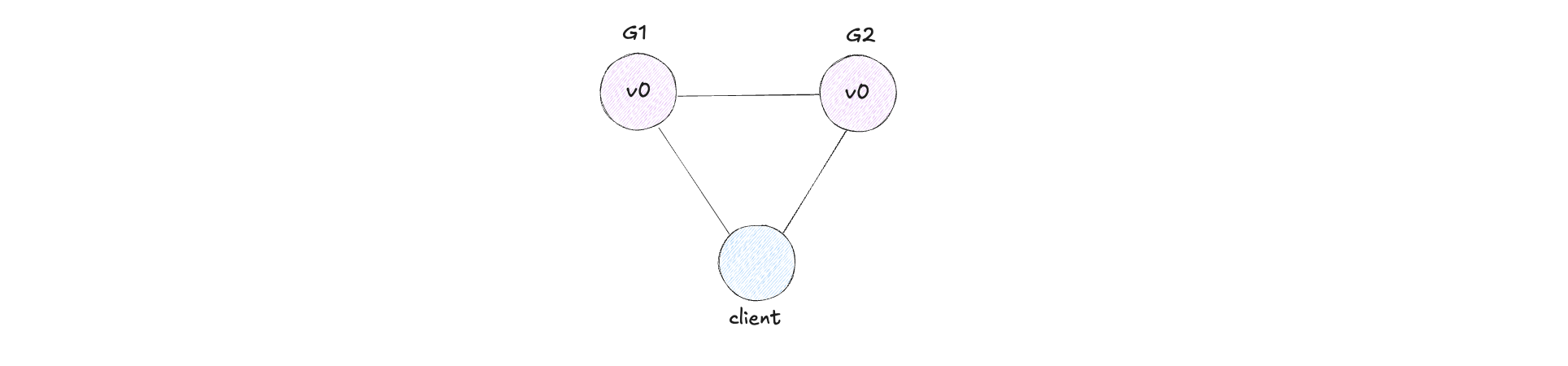
To be partition tolerant, the system must keep functioning despite this communication failure.
Because partitions are inevitable in real networks, distributed systems must handle them. During a partition, CAP leaves two choices:
- choose Consistency (CP), or
- choose Availability (AP).
CP - Consistency and Partition Tolerance
A CP system may reject requests or time out during partition to preserve correctness.
Use this when business requirements demand strict correctness and atomic behavior.
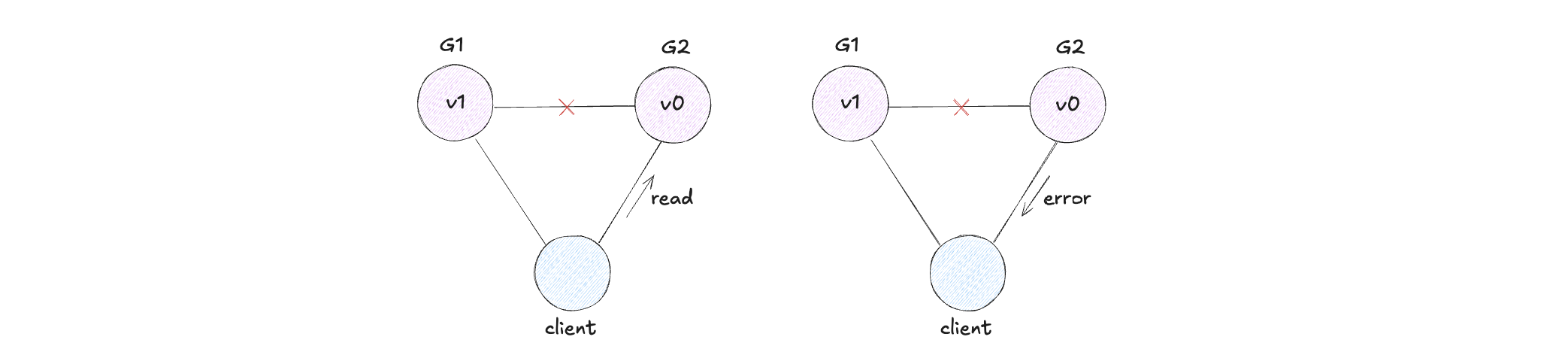
AP - Availability and Partition Tolerance
An AP system keeps responding during partition, even if some responses are stale or conflicting.
These conflicts are usually resolved later (e.g., vector clocks or domain-specific merge logic).
Use this when uptime and responsiveness are more critical than immediate consistency.
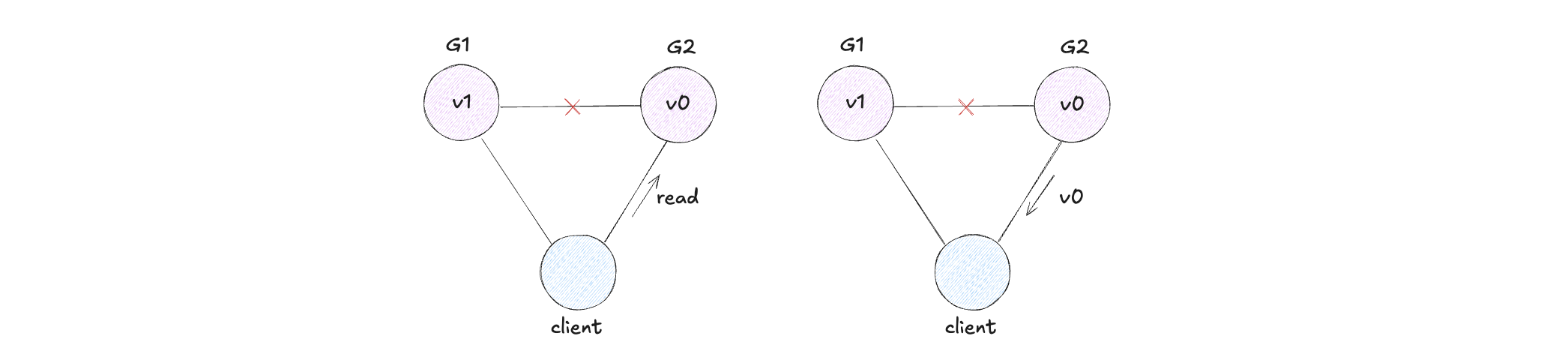
In failures, what should a system sacrifice: consistency or availability?
- Choosing Consistency Over Availability
When consistency is prioritized, the system may reject writes, reject reads, or only serve requests from a safe partition. Some requests may fail to preserve correctness.
- Choosing Availability Over Consistency
When availability is prioritized, the system responds to all requests, possibly with stale data and conflicting writes, then reconciles later.
The Proof (Intuition)
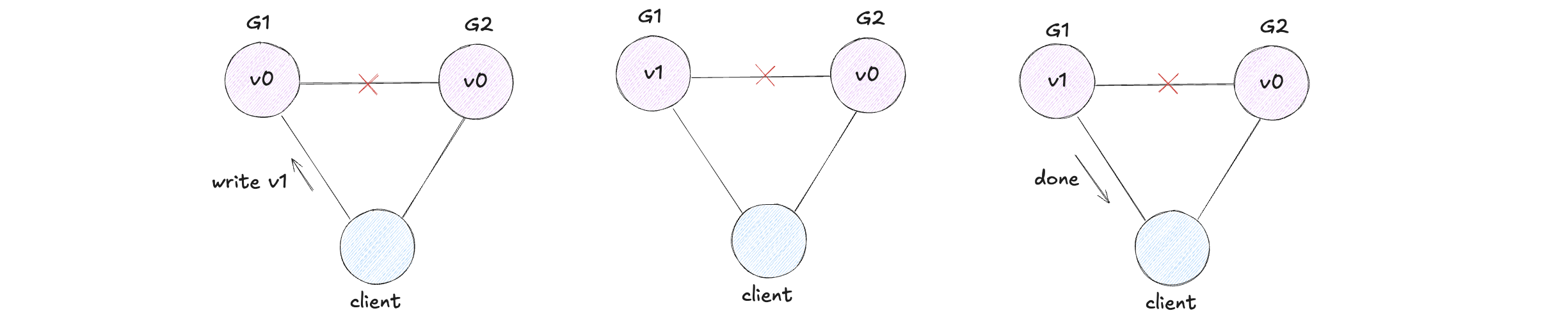
Suppose, for contradiction, there exists a system that is simultaneously consistent, available, and partition tolerant.
First, a partition happens:
Client writes v1 to G1. Because system is available, G1 must respond. But due to partition, G1 cannot replicate to G2.
Then client reads from G2. Since system is available, G2 must respond. But G2 cannot receive updates from G1, so it returns v0.
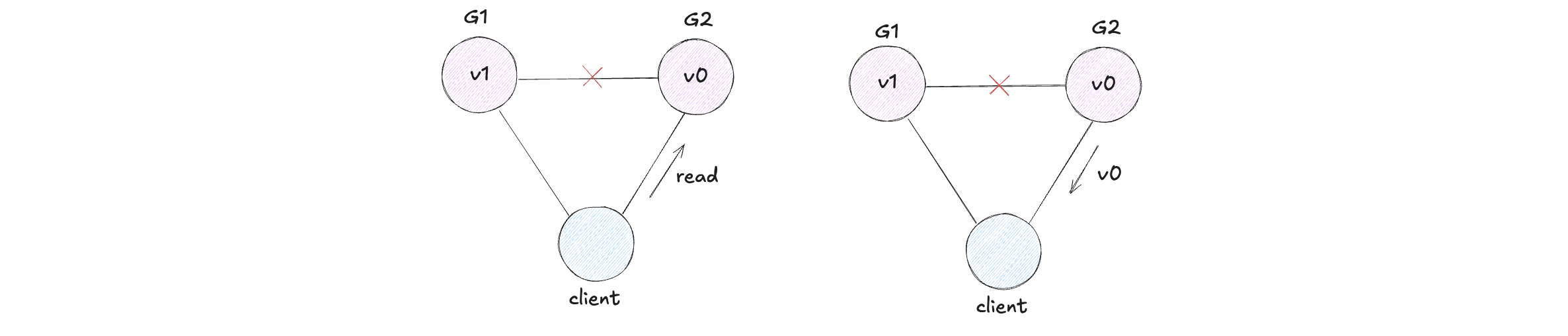
Now the client has written v1 but reads v0, which violates consistency.
So our assumption is false: no distributed system can guarantee consistency, availability, and partition tolerance all at once under partition.
Conclusion
These are my thoughts on CAP theorem and its practical trade-offs.
I hope this article is useful. If you need help, feel free to leave a comment.
Let's connect on Twitter and LinkedIn.
Thanks for reading. See you next time.