In the previous article, I shared how I built a URL shortener and mentioned that I chose the Twitter Snowflake algorithm for ID generation.
In this post, I explain why.
Context
In distributed systems, generating unique IDs is essential for use cases such as:
- logging
- sharding
- consistency across nodes
The options I considered were:
- Multi-master replication
- UUID
- Ticket server
- Twitter Snowflake
Let’s walk through each approach and compare trade-offs.
Multi-Master Replication
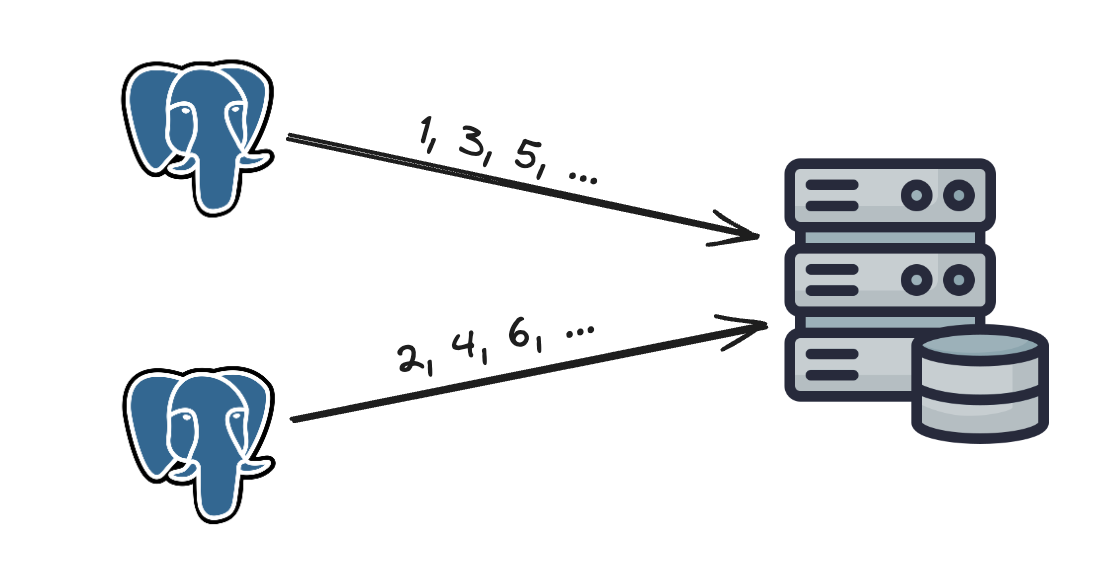
This strategy uses database auto_increment.
Instead of increasing by 1, each server increments by k (where k is the number of DB servers). This avoids immediate collisions across servers.
However, it has drawbacks:
- adding/removing servers is complicated
- operationally fragile at scale
- poor flexibility as topology changes
UUID
UUID means Universally Unique IDentifier. It is a 128-bit identifier with extremely low collision probability and no central coordination requirement.
UUID collisions are not impossible, but the probability is negligible in practice.

UUIDs are great for distributed generation, but in my URL shortener context, 128-bit IDs are longer than desired.
Ticket Server
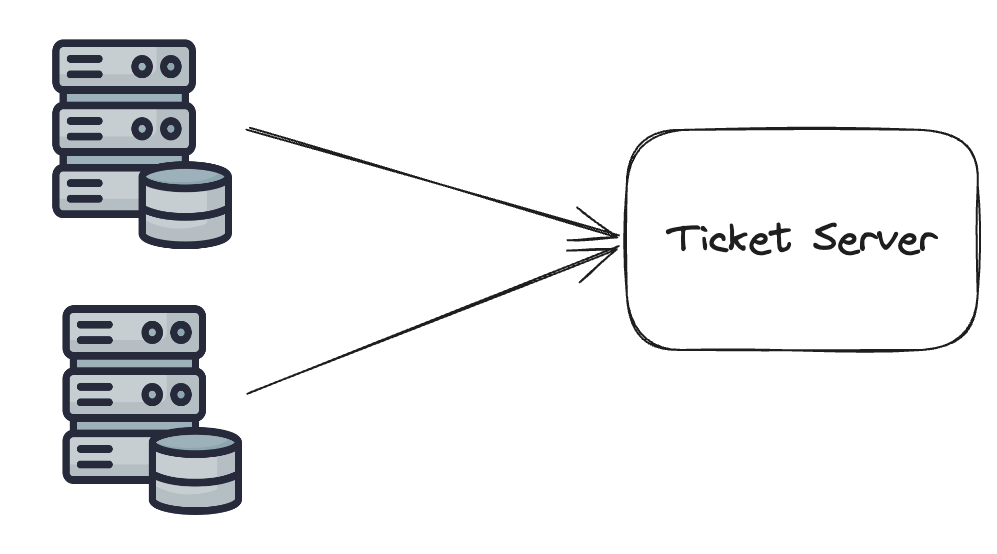
A ticket server is a centralized service (usually backed by DB auto_increment) that allocates IDs to all other servers.
Main downside:
- single point of failure
If the ticket server is unavailable, ID generation for the entire system is affected.
Twitter Snowflake
Snowflake generates unique 64-bit IDs (time-based, not globally sequential in simple numeric order). It is widely used at Twitter for entities like Tweets, users, and messages.
Each ID is composed of:
- timestamp
- worker ID
- sequence number

Sign Bit
Reserved bit (always 0 in standard usage). It can be kept for future extension and keeps the number positive.
Timestamp
Snowflake uses millisecond precision. With 41 bits for timestamp:
- max value:
2^41 - 1 = 2,199,023,255,551ms - lifespan: roughly 69 years
You can choose a custom epoch closer to your system start date to maximize useful lifetime.
Worker ID
Worker ID is generally assigned at startup and should remain stable to avoid collisions.
With 10 bits, you can support up to:
2^10 = 1,024workers
Sequence
Sequence uses 12 bits:
2^12 = 4,096values per millisecond per worker
It increments only when multiple IDs are generated in the same millisecond on the same worker.
Conclusion
Snowflake was the best fit for my case because:
- It is 64-bit, much shorter than UUID (128-bit).
- It scales well (
1,024workers and high per-ms throughput). - It is highly available with local generation per worker.
- IDs are sortable by time, which helps with operational/debugging workflows.
That is all for this article.
If you need help, feel free to leave a comment.
Let's connect on Twitter and LinkedIn.
Thanks for reading. See you next time.